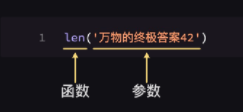
解题思路
分析问题,明确结果
思考需要的知识
思考切入点
尝试解决一部分
重复1-4步
转义字符 \a 响铃(BEL)
\b 退格(BS)将当前位置移动到前一列
\f 换页(FF)将当前位置移动到下一页开头
\n 换行(LF)将当前位置下行开头
\r 回车(CR)将当前位置移动到本行开头
\t 水平制表(HT)(跳到下一个TAB位置)
\v 垂直制表(VT)
\\ 代表一个反斜线字符 “"
\' 代表一个单引号
\'' 代表一个双引号
\0 空字符
\ddd 1到3位八进制所代表的任意字符
\xhh 1到2位十六进制所代表的任意字符
Print Print():
单引号不管啥都可打印
双引号可以引出内容的标点符号
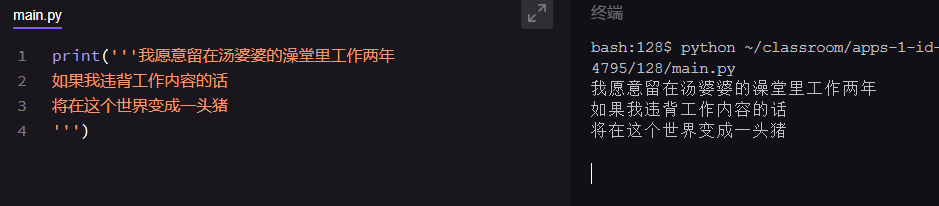
三引号跨行输出具体
/n实现换行:
Print(XXX,/nXXX,/nXXX)
变量&赋值 赋值 例:
1 2 3 name='小埋' print (name)输出:小埋
变量 例:
1 2 3 4 name='小埋' name='02' print (name)输出:02
变量的命名规范
只能是一个词
只能包含字母
不能以数字开头
尽量描述包含数据的内容
不能使用python函数名或关键字
数据类型&应用&转换 类型
字符串(string - str):
类型有:现实的词,语句,表达式
整数(integer - int):
不带小数点的数字,正负都可
浮点数(float):
带小数点的数字,运算结果存在误差
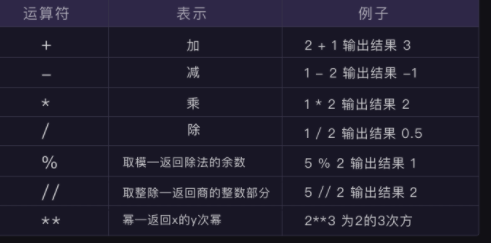
应用 四则运算:符号
字符串拼接:
类型相同 +号拼接
数据类型的查询——type()函数
例:print(type('查询的内容'))
数据转换 Str()函数:将其他数据类型转换成字符串 (也可用引号转换)
1 2 例:number = 153 ,code = '通行密码' print (who+destination+code+action+str (number))
Int()函数:将其他数据类型转换成整数 (直接抹零不做四舍五入处理)
1 2 3 4 5 例:number1 = '6' number2 = '1' print (int (number1)+int (number2)) 浮点形式的字符串 print (int ('3.8' ))不能转换, 浮点数 print (int (3.8 ))可以
Float() 函数:将其他数据类型转换成浮点数(字符串也可,除文字类字符串😅)
条件判断&嵌套 条件判断
单项判断 if:
#条件后记得跟进英文冒号,回车后自动缩进
双向判断 if…else… :
1 2 3 4 if XXXX : Print(XXXX) else : print (XXXX)
多项判断 if…elif…else… :
1 2 3 4 5 6 7 8 if XXXX : Print(XXXX) elif XXXX: Print(XXXX) elif XXXX: Print(XXXX) else : Print(XXXX)
if嵌套 if嵌套执行顺序:
#根据层级执行
#缩进相同的命令同等级,一条一条处理
1.先赋值
2.代码组1——不满足60直接跳到代码组2
3.代码组2——代码组1未满足执行
input()函数 结果必须赋值
使用:
input('XXXX')
#提问&收集数据
结果赋值:
数据类型:
input返回的类型是 str(字符串)
赋值时需要转换:
abc = 'XX'
input输出结果强制转换:
1 Abc = int(input('XXXX'))
解题思路例
函数结果赋值
搜集信息
条件判断
#2.1强制转换 #另一种情况
#3.1条件判断 #另一种情况
条件判断
输出结果
列表&字典&元组 列表
列表内偏移量起始值为0
提取单个元素:
1 2 A = [01,02,03] Print(a[0 ])
提取多个元素:
切片口诀:左右空,取到头;
左取右不取 #冒号是切片
1 2 3 4 5 6 A = [1 ,2 ,3 ,4 ,5 ] Print(a[:]) Print(a[2 :]) Print(a[:2 ]) Print(a[1 :3 ]) Print(a[2 :4 ])
注: 大小A是一个意思,都是列表A,为了不混淆记忆才这么标的,正式编码时要统一
列表添加/删除元素:
1 2 3 4 5 6 添加:append()函数 用法: 列表名.append() 注:每次只能增加一个元素 删除:del 语句 用法: del 列表名[元素的索引(偏移量)]
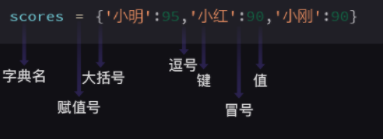
数据类型:字典 与列表不同处:大括号
字典里的元素由 键值对 组成键 (key)95叫值 (value)
Len()函数 #查询字典或列表长度(元素个数)
例:
1 2 3 4 a = ['5' ,'6' ,'7' ,'8' ] b = {'明' :12 ,'刚' :13 ,'王' :14 } print (len (a)) print (len (b))
增加键值对:
1 2 字典名['XXX'] = 值 例:字典1['psp'] = 'ppspp'
删除键值对:
1 2 Del 字典名[键] 例:del 字典2['03']
字典与列表的异同
不同点: 列表中元素位置明确,即使元素相同
相同点:
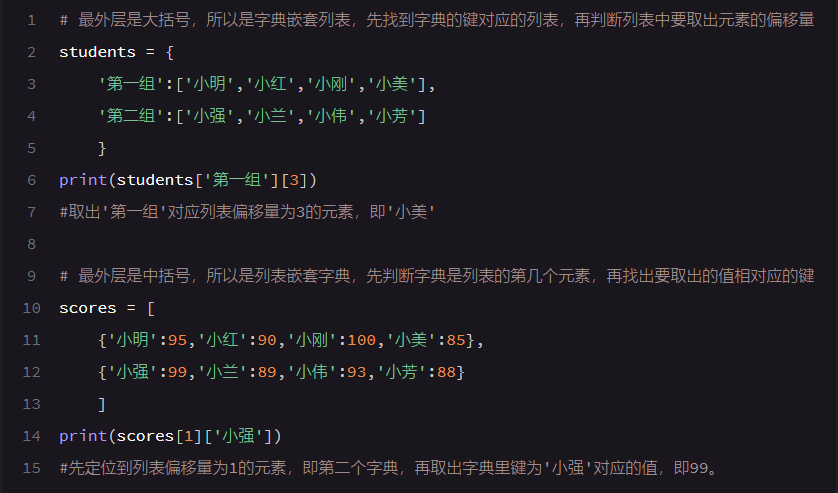
2.支持任意嵌套和互相嵌套例:
元组tuple 用小括号包,其他与列表一样
例:
1 2 3 4 tuple1 = ('A' ,'B' ) list2 = [('A' ,'B' ),('C' ,'D' ),('E' ,'F' )] print (tuple1[0 ]) print (list2[1 ][1 ])
循环注 1 2 3 4 5 知道次数优先for循环 不知道用while循环设置`哨兵` #哨兵意思大概是循环极限次数
for…in循环 第一种 1 2 3 for i in [1 ,2 ,3 ,4 ,5 ]: print (i)
第二种 1 2 3 for o in range (11 ): print ('第' +str (o)+'天' )
Range(x)函数:
1 2 3 从0生成X-1整数序列 例:range(a,b,c) 从 a 数到 b-1(取头不取尾),间隔为 C
1 2 3 例: for i in range (0 ,10 ,2 ) Print(i)
1 2 3 4 5 6 7 range (a,b,c)a:计数从a开始,不填时,默认从0 开始 b:计数到b结束,不包括b c:计数的间隔,不填时默认为1
第三种 1 2 3 4 d = {'小明' :'醋' ,'小红' :'油' ,'小白' :'盐' ,'小张' :'米' } for q in d: print (d[q])
第四种 1 2 3 for m in range (1 ,8 ): if m != 4 : print (m)
从零到100分别x5 1 2 for q in range (1 ,101 ): print (q*5 )
while循环 第一种 1 2 3 4 a = 0 while a < 5 : a = a + 1 print (a)
第二种 1 2 3 4 5 man = '' while man != '有' : man = input ('有没有愿意为小龙女死的男人?没有的话就不能出古墓。' ) print ('小龙女可以出古墓门下山啦~' )a = 0
第三种 1 2 3 4 5 6 7 while a < 5 : print ('现在a的值是:' + str (a)) a = a + 1 print ('加1后a的值是:' + str (a)) print (a)
从零到100分别x5 1 2 3 while a<101 a=a+1 print (a*5 )
pop()函数 **提取:**取到元素,对列表没有影响;
**删除:**删除列表的元素。
**pop()**函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
语法:
1 2 3 list.pop(obj=list[-1]) #默认为index=-1,删除最后一个元素。 obj是可选参数,也可以指定元素对象。
例:
1 2 3 4 5 6 7 students = ['小明' ,'小红' ,'小刚' ] for i in range (3 ): student1 = students.pop(0 ) students.append(student1) print (students)
布尔值与布尔运算 用数据做逻辑的过程叫 布尔运算
运算产生布尔值
布尔值分 true(真)和 false(假)
比较运算符:
1 2 3 4 5 6 等于: == 不等于: != 大于: > 小于: < 大于等于: >= 小于等于: <=
布尔运算:
1 2 3 4 bool ()函数: 括号里放入判断用数据,判断真假 打印出来: print (bool (XXXX))
两个数值做比较:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 And: Ture and true 真 True and false 假 False and true 假 False and false 假 or: True and true 真 True or false 真 False or true 真 False or false 假 Not: Not true 假 Not false 真
break语句 循环内部使用
if…break 意思是满足某一条件,提前结束循环
1 2 3 4 5 for 循环写法: for ……in ……: … If ….: Break
1 2 3 4 5 while 循环写法: while XXXX: … If …: Break
while例子:
1 2 3 4 5 6 While ture : print ('上供一对童男童女' ) t = input ('孙悟空来了吗' ) if t == '来了' : break print ('孙悟空制服了鲤鱼精,陈家庄再也不用上供童男童女了' )
concinue语句 满足条件继续执行下一个,不满足提前重置循环
continue语句搭配for循环 1 2 3 4 5 for ...in … : ... if ...: continue ...
continue语句搭配while循环 1 2 3 4 5 while ...XXXX: ... if ...: continue ..
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 while True : q1 = input ('第一问:你喜欢萝莉吗?' ) if q1 != '喜欢' : continue print ('答对了,行,下面第二问:' ) q2 = input ('三次元还是二次元的' ) if q2 != '二次元' : continue print ('答对了,看来是同道中人,下面第三问:' ) q3 = input ('对三次元萝莉有兴趣吗' ) if q3 == '没有' : break print ('欢迎来到萝莉社' )
pass语句 满足跳过,不满足继续执行
例:
1 2 3 4 5 a = int (input ('请输入一个整数:' )) if a >= 100 : pass else : print ('你输入了一个小于100的数字' )
else语句 else还可搭配for循环和while循环
注:别跟傻狗似的看见 i 又迷惑了,i 等于缩进下的指令
注:a 是循环用的,没看见夹中间了吗
for例 1 2 3 4 5 6 7 for i in range (5 ): a = int (input ('请输入0来结束循环,你有5次机会:' )) if a == 0 : print ('你触发了break语句,循环结束,导致else语句不会生效。' ) break else : print ('5次循环你都错过了,else语句生效了。' )
while例 1 2 3 4 5 6 7 8 9 i = 0 while i < 5 : a = int (input ('请输入0结束循环,你有5次机会:' )) i = i+1 If a == 0 : print ('你触发了break语句,导致else语句不会生效。' ) break else : print ('5次循环你都错过了,else语句生效了。' )
当循环中没有碰到break语句,就会执行循环后面的else语句,否则就不会执行
import函数 意:导入模块函数
上例 1 2 3 4 import time time.sleep(secs)
模块 1 2 3 4 5 Random模块下 randint()函数 #随机整数 用法:random.randint(1,100) #1-100随机整数 Time模块下 sleep()函数 #间隔时间
代码视觉优化 格式化字符串:
%后面有一个字母s,这是一个类型码
用来控制数据显示的类型。%s就表示先占一个字符串类型的位置
第一种 1 2 3 4 5 lucky = 8 print ('我的幸运数字是%d' % lucky) print ('我的幸运数字是%d' % 8 ) print ('我的幸运数字是%s' % '816' ) print ('我的幸运数字是%d和%d' % (8 ,16 ))
%后面补上要填的内容,省掉转换类型,多个数据就放进括号
%s 字符串显示
%f 浮点数显示
%d 整数显示
第二种(更方便) format()函数:
例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 format ()格式化函数:str .format () print ('\n{}{}' .format ('数字:' ,0 )) print ('{},{}' .format (0 ,1 )) print ('{1},{0}' .format (0 ,1 )) print ('{0},{1},{0}' .format (0 ,1 )) name2 = 'Python基础语法' print ('我正在学{}' .format (name2))
函数 定义 函数是组织好的,可以重复使用的,用来实现单一功能的代码
组成
参数=自变量
定义函数 语法:
1 2 3 def 函数名(参数名): 函数体 return 语句
例:
1 2 3 4 5 6 7 8 9 def math (x ): y = 3 *x + 5 return y
调用函数 话不多说,直接上例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def math (x ): y = x ** 2 + x return y x=math(10 ) print (x) 也有这种例子: def opening (): print ('总有一种味道能温暖你~' ) print ('深夜食堂正式开业啦!' ) print ('欢迎来自五湖四海的你前来品尝!' ) opening()
参数类型 【位置参数】上例开讲:
1 2 3 4 5 6 7 8 9 def menu (appetizer, course ): print ('一份开胃菜:' + appetizer) print ('一份主食:' + course) menu('话梅花生' ,'牛肉拉面' ) menu('花生' ,'面' ) menu(course = '面' , appetizer = '花生' )
列表传参:
1 2 3 4 5 6 7 8 def bala (food ): for x in food: print (x) fruits = ["apple" , "banana" , "cherry" ] bala(fruits)
【不定长参数】上例开讲:
1 2 3 4 在不知道传递给函数的参数数量时在参数前面加个*号 例: def menu (*barbeque ):
返回多个值 上例才能理解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import random appetizer = ['话梅花生' ,'拍黄瓜' ,'凉拌三丝' ] def coupon (money ): if money < 5 : a = random.choice(appetizer) return a elif 5 <= money < 10 : b = random.choice(appetizer) return b, '溏心蛋' result = coupon(6 ) print (result[0 ])print (result[1 ])dish, egg = coupon (7 ) print (dish)print (egg)
变量作用域 我去了,读了3个小时才完全理解
说明: 上例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 rent = 3000 def cost (): global variable_cost utilities = int (input ('请输入本月的水电费用' )) food_cost = int (input ('请输入本月的食材费用' )) variable_cost = utilities + food_cost print ('本月的变动成本是' + str (variable_cost)) def sum_cost (): sum = rent + variable_cost print ('本月的总成本是' + str (sum )) cost() sum_cost()
函数的嵌套 上例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def div (num1, num2 ): growth = (num1 - num2) / num2 percent = str (growth * 100 ) + '%' return percent def warning (): print ('Error: 你确定上个月一毛钱都不赚不亏吗?' ) def main (): while True : num1 = float (input ('请输入本月所获利润' )) num2 = float (input ('请输入上月所获利润' )) if num2 == 0 : warning() else : print ('本月的利润增长率:' + div(num1,num2)) Break main()
练习: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 def buff (month ): if month<6 : a = 500 return a elif 6 <= month <= 12 : b = month * 120 return b else : c = month * 180 return c def gamer (): name = input ('输入名字:' ) month = float (input ('干了几个月?' )) print (name,month,'个月' ,'奖金:' ,buff(month)) gamer()
index函数 index()函数用于找出列表中某个元素第一次出现的索引位置。
语法为:列表名字.index(查找对象名字)
例:
1 2 3 4 num = [0 ,1 ,0 ,1 ,2 ] print (num.index(1 )) print (num.index(2 ))
可能比较难理解,上大例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import randompunches = ['石头' ,'剪刀' ,'布' ] computer_choice = random.choice(punches) user_choice = '' user_choice = input ('请出拳:(石头、剪刀、布)' ) while user_choice not in punches: print ('输入有误,请重新出拳' ) user_choice = input () print ('————战斗过程————' )print ('电脑出了:%s' % computer_choice)print ('你出了:%s' % user_choice)print ('—————结果—————' )if user_choice == computer_choice: print ('平局!' ) elif user_choice == punches[punches.index(computer_choice)-1 ]: print ('你赢了!' ) else : print ('你输了!' )
try…except语句 语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 try : XXX XXX Except 报错名称: XXX XXX Except 报错名称: XXX XXX 方式2 :将两个(或多个)异常放在一起,只要触发其中一个,就执行所包含的代码。 except (ZeroDivisionError,ValueError): print ('你的输入有误,请重新输入!' ) 方式3 :常规错误的基类,假设不想提供很精细的提示,可以用这个语句响应常规错误。 except Exception: print ('你的输入有误,请重新输入!' )
例子: 1 2 3 4 5 6 7 8 9 10 11 while True : try : age = int (input ('你今年几岁了?' )) Break except ValueError: print ('你输入的不是数字!' ) if age < 18 : print ('不可以喝酒噢' )
debug方法 自检清单:
漏了末尾冒号
缩进错误
中英文符号没变
没有定义变量
‘==’ 和 ‘=’ 混用
字符串拼接时将数字和字符串拼一起了
解决思路不清:
#号和 print() 函数搭配使用,一段段检查代码
类 简单总结: 类的创建: class语句
类的属性创建: 赋值语句
实例方法的创建: def 名字(self):
类的实例化: 实例名 = 类名( )
调用类的属性: 实例名.属性
调用类的方法: 实例名.方法( )
什么什么类的东西
例如电子设备,list #列表类
不同点: 现实中的类的属性和方法是客观存在的
编程中类的属性和方法是人工创建的
类是存在共同点的 第一种叫属性(attribute)
第二种叫方法(method)
例如:列表的属性有:外层有中括号,元素之间用英文逗号隔开
方法有:都可以做增删改操作(如 append、del等)
类的创建: 1 2 3 4 5 6 7 class Computer : screen = True def start (self ): print ('电脑正在开机中……' ) 注:实例方法是指类中 参数 带self 的函数,是类方法的一种形式,也是最常用的用法,其他方法可查档
类的调用: 类的实例化:
在某一个类下创建个实例对象:
1 2 3 语法:实例名 = 类名() 例子:这是想到的实例名 = 这是刚创建的类名加个( ) 意义:有了一个可调用 所属类 的 所有属性 和 方法 的实例
例例例:
1 2 3 4 5 6 7 8 9 10 11 12 13 class people : eye = 'black' def chpe (self ): print ('吃饭,选择用筷子。' ) my_eye = people() print (my_eye.eye) my_eye.chpe()
创建类的两个关键点 特殊参数:self
作用: self会接收实例化过程中传入的数据,相当于先给实例占个位置
想要在类的外部调用类属性格式:self.属性名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 **例:** class Chinese : def greeting (self ): print ('很高兴遇见你' ) def say (self ): self.greeting() print ('我来自中国' ) person = Chinese() person.say()
初始化方法:
格式: def init (self):
作用: 当每个实例创建时,该方法内代码无需调用就会自动运行
类的继承&定制 所有实例的根类: object
创建类时不带括号,运行时默认为 class XXX (object):
各级实例和各级类间的关系:
子类创建的实例,同时属于父类
父类创建的实例,不属于子类
所有实例,都属于根类object
类的继承 基本语法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class people : eye = 'black' def chpe (self ): print ('吃饭,选择用筷子。' ) class people2 (people ): pass doge = people2 ( ) print (doge.eye)doge.chpe( )
函数: isinstance() 1 2 3 4 5 6 7 可以判断某个实例是否属于某个类 用法: isinstance (实例,类) 例子: 判断 1 是否属于整数类的实例: isinstance (1 ,int ) 输出true
多层继承 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 语法: class B (A ):… class C (B ):作用: 类在纵向上的深度拓展 例子: 父亲继承自爷爷,儿子继承自父亲 特点: 子类创建的实例,可调用所有层级的父类的属性和方法
多重继承 1 2 3 4 5 6 7 8 9 10 11 12 13 语法: class A (B,C,D):作用: 类在横向上的宽度拓展 例子: 儿子同时继承了父母的一些特征 特点: 就近原则:在子类调用属性和方法时,优先考虑离得近的子类(即靠左)的父类。
综合例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class C0 : name = 'C0' class C1 : num = 1 class C2 (C0 ): num = 2 class C3 : name = 'C3' class C4 (C1,C2,C3): pass out = C4() print (C4.name) print (C4.num)
类的定制 新增代码 用法例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Chinese : eye = 'black' def eat (self ): print ('吃饭,选择用筷子。' ) class Cantonese (Chinese ): native_place = 'guangdong' def dialect (self ): print ('我们会讲广东话。' ) yewen = Cantonese() print (yewen.eye)print (yewen.native_place)yewen.eat() yewen.dialect()
重写代码 用法例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Teacher : face = 'serious' job = 'teacher' class Father : face = 'sweet' parenthood = 'dad' class TeacherMore (Teacher, Father): pass class FatherMore (Father, Teacher): face = 'gentle'
综合例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Student : def __init__ (self, name, job=None , time=0.00 , time_effective=0.00 ): self.name = name self.job = job self.time = time self.time_effective = time_effective def count_time (self, hour, rate ): self.time += hour self.time_effective = hour * rate class Programmer (Student ): def __init__ (self, name ): Student.__init__(self, name, job='programmer' , time=0.00 , time_effective=0.00 ) def count_time (self, hour, rate=1 ): Student.count_time(self, hour, rate) student1 = Student('韩梅梅' ) student2 = Programmer('李雷' ) print (student1.job) print (student2.job) student1.count_time(10 ,0.8 ) student2.count_time(10 ) print (student1.time_effective) print (student2.time_effective)
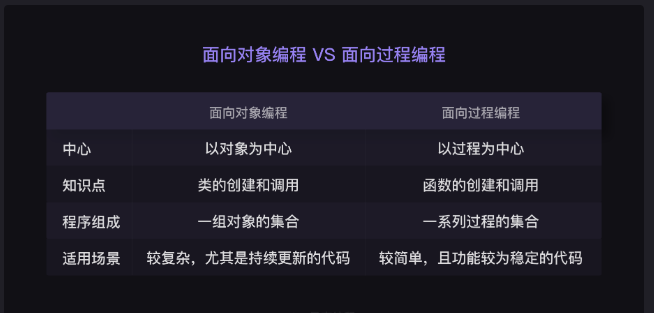
面向对象编程 面向对象编程,会将程序看作是一组对象的集合
1 2 3 4 5 6 7 8 9 10 11 12 面向对象编程实际上也是一种对代码的封装。 只不过,类能封装更多的东西,既能包含操作数据的方法, 又能包含数据本身。所以,代码的可复用性也更高 将代码具体的数据和处理方法都封装在类中, 让我们不用完全了解过程也可以调用类中的各种方法。 这个优势让我们可以在 Python 中轻松地调用各种标准库、第三方库和自定义模块 (可以简单理解成别人写好的类) 大概就和css里的样式差不多
__str__(self):特殊方法 : __str__(self)
使用print打印方法时直接打印方法return的数据,不用调用了
两个例子: 没用__str__(self) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def show_info (self ): if self.state == 0 : status = '未借出' else : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) book1 = Book(' 像自由一样美丽 ' , ' 林达 ' , ' 你要用光明来定义黑暗,用黑暗来定义光明 ' ) print ( book1.show_info( ) )
用了__str__(self) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class Book : def __init__ (self, name, author, comment, state = 0 ): self.name = name self.author = author self.comment = comment self.state = state def __str__ (self ): if self.state == 0 : status = '未借出' else : status = '已借出' return '名称:《%s》 作者:%s 推荐语:%s\n状态:%s ' % (self.name, self.author, self.comment, status) book1 = Book(' 像自由一样美丽 ' , ' 林达 ' , ' 你要用光明来定义黑暗,用黑暗来定义光明 ' ) print ( book1 )
编码&文件读写 二进制 逢2进1
1 2 3 4 5 6 7 8 9 10 例: 二进制 = 十进制 000 = 0 001 = 1 010 = 2 011 = 3 100 = 4 101 = 5 110 = 6 111 = 7
计算机最小储存单位: 1 2 3 4 【位】 也叫 【比特】(bit) 用来存放0和1 8位等于1个 字节(byte) 最常用的单位 也就是:00000000 全为1时: 11111111 等于255
编码表: 1 2 3 4 5 6 7 8 9 10 11 12 ASCII 英文大小写, 字符, 不支持中文 GB2312, GBK码 支持了中文 GBK码是GB2312的升级 Unicode码 支持了国际语言 占用空间大, 适应性强 UTF-8 支持了国际语言 是国际语言 是Unicode的升级, 两者可以非常容易互相转化, 占用空间小, ASCII码被UTF-8码包含 8进制: 0,1,2,3,4,5,6,7 表示方法 16进制: 0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f 表示方法 # 没有具体介绍
encode()和decode() 1 2 3 4 5 6 7 8 9 encode()编码 用法:'准备编码的内容'.encode('编码表') decode()编码 用法:'准备解码的内容'.encode('编码表') 最前面有一个字母b, 比如b'\xce\xe2\xb7\xe3' 这代表它是bytes(字节)类型的数据 \x是分隔符, 用来分隔一个字节和另一个字节 网址里面有%, 它也是分隔符
文件 开 写 关
open函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 例: open('文件路径', 'r', encoding='utf-8') 第一个参数:文件路径 绝对路径: 双反斜杠: 'C:\\XXX\\XXX\\XXX\\XXX.txt' 不用处理直接读取 单反斜杠: r'C:\XXX\XXX\XXX\XXX' 前面加上小写R, 因为单斜杠在py里是转义字符 相对路径: 不在文件夹:'XXX.txt' 在文件夹:'XXX/XXX.txt' 第二个参数:'r' 表示read 以读的模式打开文件 'w' 表示write 写入方式 'w'写入模式会暴力清空掉文件,然后再写入 'a'表示append 增加,追加内容 第三个参数: 表示的是返回的数据采用何种编码,一般采用utf-8或者gbk。注意这里是写encoding而不是encode file1 = open('/Users/Ted/Desktop/test/abc.txt','r',encoding='utf-8') file2 = file1.read() #读取内容并放在file2里 .read() 读取内容 .write('准备写入的东西') 写入内容 print(filecontent) file1.close() #关闭文件 ,因为:1.计算机打开文件数量有限 2.能保证写入内容已经保存好
普通写法 1 2 3 4 5 file1 = open ('abc.txt' ,'a' ) file1.write('写些什么' ) file1.close()
使用with关键字的写法 1 2 3 4 5 6 7 8 9 10 11 12 with open ('abc.txt' ,'a' ) as file1:with open ('文件地址' ,'读写模式' ) as 变量名: file1.write('写些什么' )
模式
模式
描述
t
文本模式(默认)
x
写模式,新增文件,如文件已存在会报错
b
二进制模式
+
打开文件进行更新(可读可写)
r
只读方式打开
rb
以二进制只读方式打开
r+
打开文件用于读写
rb+
以二进制方式文件读写
w
文件写入,存在打开从头写(原内容删除),没有会创建
wb
二进制写入,其他原理同上
w+
文件读写,其他原理同上
wb+
二进制文件读写,其他原理同上
a
文件追加,如文件存在,新内容写在原有内容后,没有会创建
ab
二进制文件追加,其他原理同上
a+
文件读追加,其他原理同上
模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import 模块名(也可以导入自己写的文件做模块格式就是文件名字没有后缀) 例: import story for i in range (10 ): print (story.sentence) story.mountain() A = story.Temple() print (A.sentence) A.reading() print () sentence = '从前有座山,' def mountain (): print ('山里有座庙,' ) class Temple : sentence = '庙里有个老和尚,' def reading (self ): print ('在讲一个长长的故事。' )
import 模块名 as 将模块名自定义化 1 2 比如:import story as s 调用从 story.方法名 变为 s.方法名
from 模块名 import 模块中的方法名: 1 2 直接导入指定部分,直接使用无需加上 模块名点 的前缀 from … import *
if__name__==’main.py ‘: 1 2 3 if__name__=='__main.py__' : 代码块 代码块
使用现有模块: 1 2 3 4 5 这有啥说的 查找模块方法 dir(模块名) 查询后结果__xx__的不用管,全英文函数是正确的 其实不用这东西,直接谷歌就行
模块总结 1 2 3 4 5 6 7 import 语句使用 import 模块名 导入模块 可以使用 import 模块名 as 自定义名 为模块取名 导入模块后,在调用模块中的变量/函数/类 的时候,要加上 模块名. 格式
1 2 3 4 5 from import 语句from 模块名 import 指定的内容导入模块,并且可以直接使用指定的内容(变量,函数,类)
1 2 3 4 5 6 if __name__ == '__main__' :通常在主模块使用,表示这是“程序的入口” 当该模块作为被导入的模块时,if __name__ == '__main__' 后面的代码不会被运行